

So, if you followed on from my last post -https://www.pdavies.io/blog/turning-old-server-into-ai-master-part-2-the-software/
I have deployed JupyterHub and Python to an old server that has an Nvidia Tesla P100 GPU. Now I want to make sure that I am actually using the GPU, so the following steps demonstrate how I run a test.
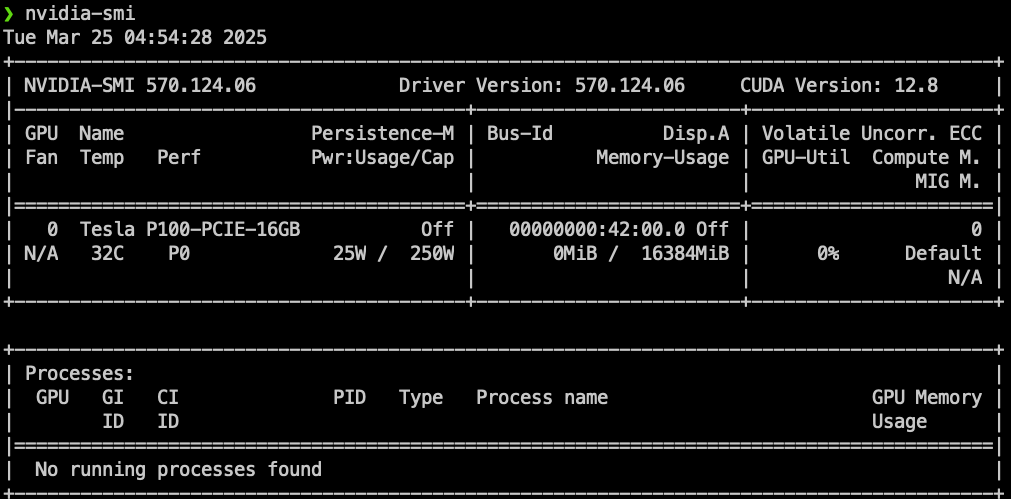
First things first, on my server, I can run nvidia-smi and it shows I have the GPU installed "hopefully" correctly!
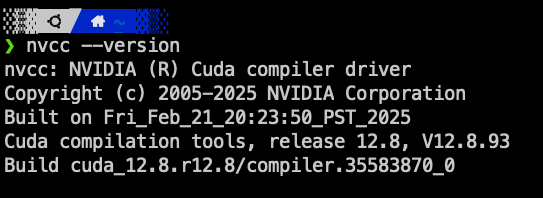
I've noticed that when running nvcc --version to check the CUDA installation, I was getting zsh: command not found: nvcc. This was frustrating since I knew the CUDA installation had been completed successfully without errors (and took a considerable amount of time).
The issue turned out to be related to path configuration. When installing CUDA from the network repositories rather than a local package, the system doesn't automatically update your PATH environment variables.
To fix this, I need to manually add the CUDA binary directory to my PATH. For a zsh shell, I added the following to ~/.zshrc file:
export PATH=$PATH:/usr/local/cuda/bin
After adding this line and running source ~/.zshrc, the nvcc --version the command works properly, confirming my CUDA installation.
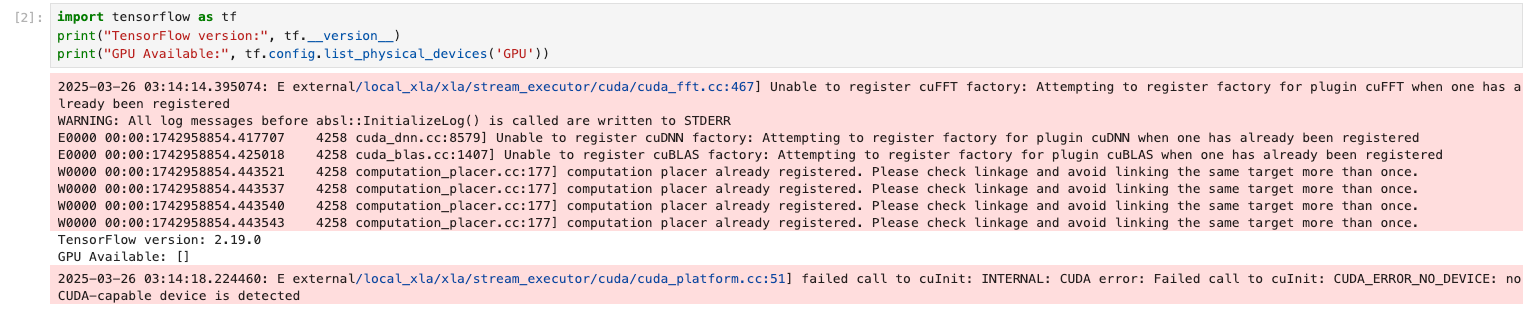
Now that's out of the way, I want to see if some python can run on the GPU, to do this I am going to use Tensorflow, it has easy command to show that it dects the GPU.
The command is:
import tensorflow as tf
print(tf.config.list_physical_devices('GPU'))So after consulting Claude.ai and ChatGPT both suggested doing the following:
sudo /opt/jupyterhub/venv/bin/pip install tensorflow-gpu
sudo /opt/jupyterhub/venv/bin/pip install cupy-cuda12x
sudo /opt/jupyterhub/venv/bin/pip install numba
Now, before I do all the other configs to get JupyterHub to work with this, I tested just by doing a local test on the command line and I can tell you this is why AI isn't going to replace everyone straight away!
When I ran the test TensorFlow could not detect the GPU:

This was so far from what was needed, and it took me a bit to piece together getting everything to work. This also caused a bit of redesign as well and that's what I am going to get into.
Get Tensorflow to use GPU
So, the errors from the above screenshot I have found are actually warnings and at the time of writing this an active issue was open for it.
The second thing was tensorflow-gpu is an older package. What was needed was tensorflow[and-cuda] , again when I wrote this I used version 2.19.0
This was still not enough to get things working, after a few more hours of digging I found I needed to install the following packages:
- cudnn9-cuda-12
The following were recommended, but in the end, I don't think they are needed unless you want to build from source:
- llvm-17
- clang-17
- bazel-platforms
- zlib1g
This got things working, when I run the test now I can see that Tensorflow has picked up the GPU:

JupyterHub and Tensorflow
Here I thought "Great! I now have it working and it should be fine," but anyone in IT knows nothing is ever that easy. So I ran the test again through my notebook and it didn't work.
So one thing led to another through the troubleshooting, I wanted to make sure Jupyter was loading the virtual environment correctly, so I ran a script to check paths and environment:
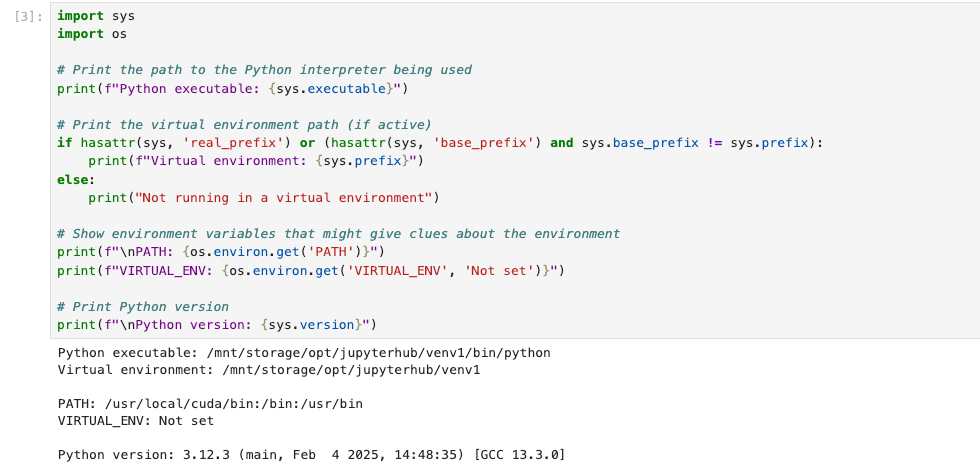
and as you can see it wasn't loading the virtual environment. I was able to get Jupyter to load the virtual environment by changing the spawner cmd to run a wrapper script that would activate the environment and then run the server:
#!/bin/bash
source /mnt/storage/opt/jupyterhub/venv/bin/activate
exec /mnt/storage/opt/jupyterhub/venv/bin/jupyterhub-singleuser "$@"This worked in activating the virtual environment, but I found that TensorFlow still was not finding the GPU 😦
The other thing that was starting to annoy me was it didn't seem like out of the box JupyterHub would work or was meant to work with different environments. Which led me to the next thing and why I redesigned a bit.
The Redesign
So JupyterHub has something called Named Servers, It is a type of spawner that allows a user to have servers(environments) with different configurations. So why do I care about this, I like the idea that in a Python environment or other you only install the libs/packages that are required, and it feels like the standard way of deploying Hub is to install everything that everyone needs and that would be shared between all hub servers (and even some of the docs hint of this).
So I want to be able to list different environments that have different package requirements for different projects. What I found that I think will do this is Named Servers, but that does not work with Systemd Spawner.
But what it does work with is Docker spawners! Ok, so let's get the docker image working and have a pass-through of the GPU.
Tensorflow Docker Image
So getting the docker image was a little pain but there where 2 main things I needed to do.
- Install NVIDIA Container Toolkit (https://github.com/NVIDIA/nvidia-container-toolkit)
The NVIDIA Container Toolkit allows users to build and run GPU accelerated containers. The toolkit includes a container runtime library and utilities to automatically configure containers to leverage NVIDIA GPUs.
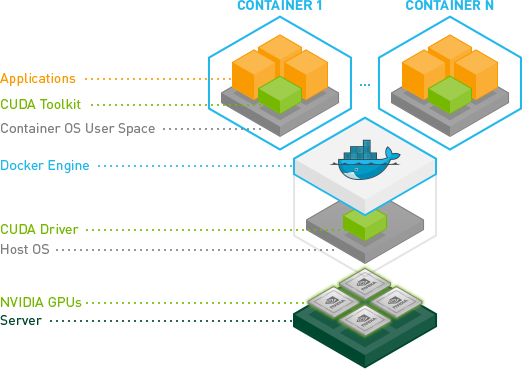
Simple install process, as per normal I turned into Ansible tasks:
- name: Add NVIDIA Container Toolkit repository
shell: |
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
become: true
- name: Update APT cache
apt:
update_cache: true
become: true
- name: Install required packages
apt:
name:
- nvidia-container-toolkit
become: true
- name: Configure nvidia-ctk runtime for Docker
command: nvidia-ctk runtime configure --runtime=docker
become: true
- name: Restart Docker
service:
name: docker
state: restarted
become: true
The two main things here is install the package and then tell the toolkit to reconfigure Docker to use GPU or allow use of the GPU!
- Update Tensorflow Docker Image
So now that docker should have access to the GPU, all the docs and ChatGPT lead me to believe that I could just use the TensorFlow Docker image and away I go, but again nothing is that simple.
To test this is what I did, run the docker image for the version of Tensorflow that I need:
> docker run --runtime=nvidia --gpus all -it --rm tensorflow/tensorflow:2.19.0-gpu-jupyter bash
making sure that I have the --runtime=nvidia --gpus all flags, the --gpus flag allows me to limit the number of GPUs to use and the --runtime should be self-explanatory!
Once the container has been downloaded and started I would run the Python console and do the same test with Tensorflow:
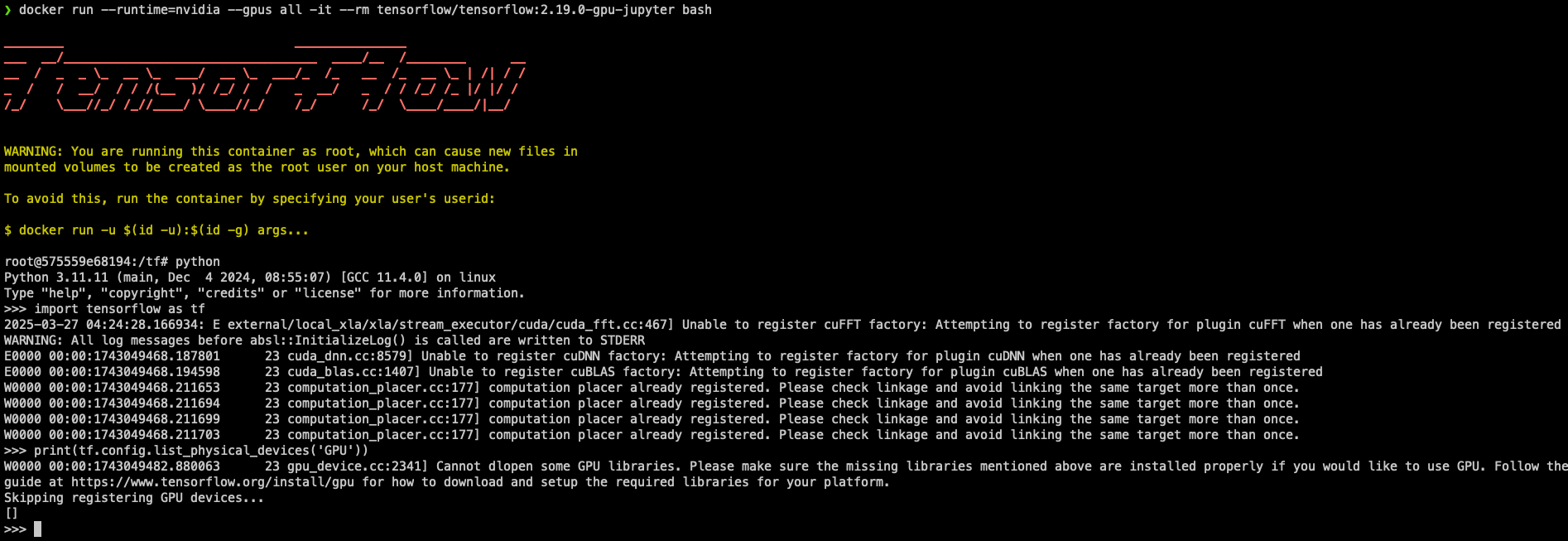
As you can see, it is still the same issue. Between Nvidia and Tensorflow sites/docs and other blogs, they all led me to believe as long as all the unlying host was set up correctly it would work.
Long and short of it, I did a pip freeze command to list all the packages that were installed in the docker container and my working Python virtual environment and found that it was missing all the Cuda and Cudnn Packages.

So as a test, I added cudnn9-cuda-11 package to my docker Image:
> apt update
> apt install cudnn9-cuda-11
> python
Python 3.11.0rc1 (main, Aug 12 2022, 10:02:14) [GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import tensorflow as tf
2025-03-27 02:07:21.060355: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:477] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
E0000 00:00:1743041241.081556 407 cuda_dnn.cc:8310] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
E0000 00:00:1743041241.088696 407 cuda_blas.cc:1418] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
>>> print(tf.config.list_physical_devices('GPU'))
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]and would you look at that, it worked!
So now that I got that to work, my plan is to build a custom docker image and configure JupyterHub with Named servers using Docker Spawner that uses that image.
So, in the next blog post, I will go through that!
